![]()
Każdy z nas lubi, gdy żmudną robotę, zamiast nas, wykonuje narzędzie. Jeszcze lepiej, gdy jest zautomatyzowane i nie potrzebuje zbyt dużo naszej uwagi. Niezależnie od tego, czy jesteśmy motywowani chęcią automatyzacji, optymalizacji pracy czy zwyczajnym lenistwem, w sukurs przychodzą crawlery internetowe – oprogramowanie webowe lub desktopowe, które skanuje serwis w celu monitoringu najważniejszych z punktu widzenia specjalisty SEO metryk i znacznie skraca czas potrzebny na przeprowadzenie analizy technicznej serwisu.Takim narzędziem jest Deepcrawl – rozwiązanie chmurowe, stworzone we współpracy dwóch specjalistów i developera w celu jak najlepszego wsparcia dla migracji dużego serwisu z nieruchomościami. Testując dostępne crawlery doszli do wniosku, że żaden z nich nie spełnia w pełni ich potrzeb i zaplanowane prace wymagają autorskiego rozwiązania. Tak powstał Deepcrawl, który aktualnie jest używany w ponad 50 krajach i jest jednym z najbardziej powszechnie stosowanych w branży SEO.
Świat crawlerów
Dla wielu specjalistów pierwszym skojarzeniem na hasło crawler jest Screaming Frog, który w szczególności w Polsce posiada duże grono fanów. Przyglądając się rynkowi web crawlerów/spiderów należy również zwrócić uwagę na narzędzia takie jak: Sitebulb, Oncrawl, JetOctopus, Seocrawler.io czy starodawny Xenu. Nie zapominajmy, że świetnie rozbudowanymi crawlerami są przede wszystkim boty Google, z których funkcjonalności możemy skorzystać w Google Search Console (np. wykrywanie duplikatów tytułów, meta description czy błędów 404).
Zauważalne jest więc, że rynek crawlerów jest dosyć konkurencyjny i każdy z produktów musi się wyróżniać, oferować funkcjonalności, które sprawią, że dane narzędzie zaistnieje na rynku. Każdy z crawlerów posiada swoje niewątpliwe zalety i ograniczenia, natomiast moim celem nie jest stworzenie ich rankingu. Zamierzam natomiast wskazać, do czego przydaje mi się Deepcrawl w czasie analizy serwisów i dlaczego nie wyobrażam sobie bez niego pracy w branży SEO.
1. Wygodny i intuicyjny Dashboard
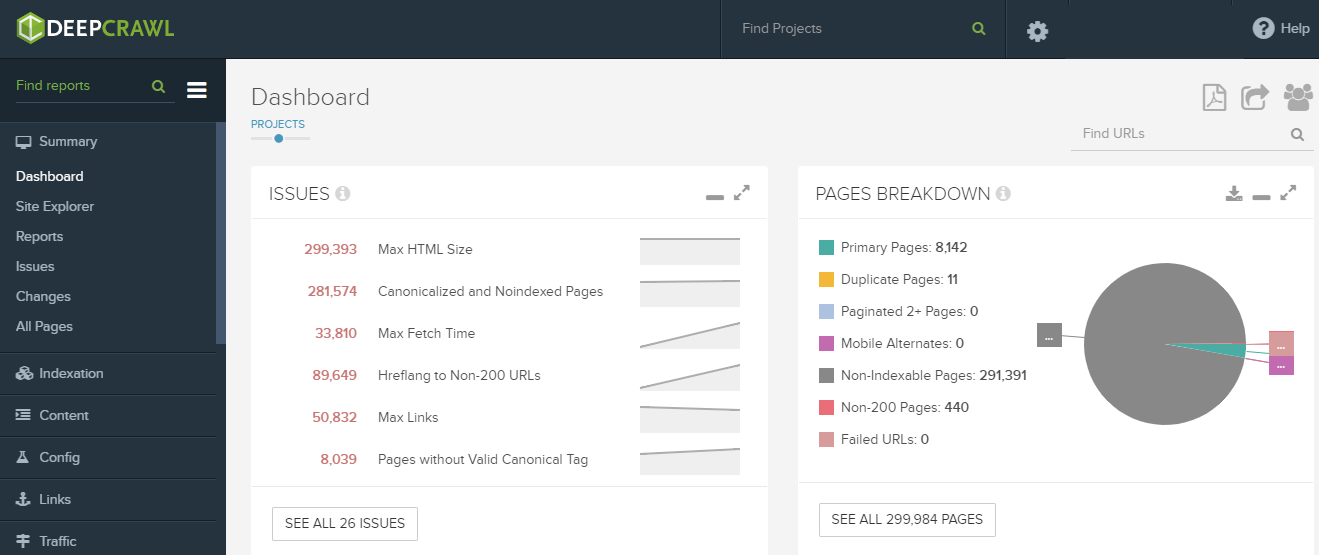
Intuicyjny Dashboard to wielka zaleta Deepcrawla
Chcąc przedstawić 10 najważniejszych/najciekawszych metryk, jakie możemy znaleźć w Deepcrawl, zaczynam od… funkcjonalności samego urządzenia, a w zasadzie sposobu, w jaki prezentuje dane. Bardzo przejrzysty dashboard, w którym znajdziemy wszystkie najbardziej istotne metryki tuż po zakończeniu crawlu pozwala nam na błyskawiczną podstawową ocenę kondycji technicznej serwisu. W sytuacji, gdy w konkurencyjnych crawlerach specjalista musi przeklikać się przez masę okienek, w Deepcrawl dostaje wszystko jak na tacy w sekcji „Issues”, która wskazuje najistotniejsze problemy, z którymi boryka się serwis wraz z liczbową wartością stron, których dany problem dotyczy. Wykresy znajdujące się poniżej prezentują inne istotne metryki, jak np. podział stron względem kodu odpowiedzi, wykres głębokości stron w strukturze serwisu czy metryka dot. wykorzystywania protokołów http i https.
2. Duplikacje treści
Deepcrawl to prawdziwy kombajn w kwestii odnajdywania i klasyfikowania przypadków duplikacji treści. Pozwala na wychwycenie praktycznie wszystkich przypadków powtarzania się, czyli:
- Duplikacji tytułów
- Duplikacji meta description
- Duplikacji sekcji body stron – bardzo przydatne w przypadkach, gdy tytuły i opisy stron są różne, natomiast treść znajdująca się pomiędzy znacznikami <body> jest identyczna lub w znacznym stopniu wzajemnie się duplikująca
- Duplikacji całej strony (body i atrybuty meta w nagłówku strony)
Jedyne, czego może brakować w kwestii duplikacji to fakt, że Deepcrawl nie analizuje pod tym kątem nagłówków H1 (wskazuje natomiast przypadki braku nagłówków H1 oraz wielokrotnej ich obecności pod danym adresem URL), które również mogą być problematyczne (np. spotkałem się z przypadkiem serwisu klienta, w którym na każdej stronie nagłówkiem H1 był jego brand). Świetnym udogodnieniem, jakie oferuje narzędzie to grupowanie przypadków duplikacji w zestawy – wszystkich stron z identycznymi tytułami, opisami meta czy treścią. Pozwala to na szybkie określenie najważniejszych powodów duplikacji oraz wyłapanie wzorów, na podstawie których tworzą się powtórzenia.
3. Strony o małej ilości treści/puste strony
Thin pages i Empty pages to kolejne bardzo istotne metryki dla powodzenia projektu SEO. Deepcrawl nie robi nic innego, tylko pokazuje nam listę stron, które (według domyślnych ustawień narzędzia) posiadają:
- Mniej niż 3072 bajty tekstu dla metryki Thin Pages,
- Mniej niż 512 bajtów tekstu dla metryki Empty Pages.
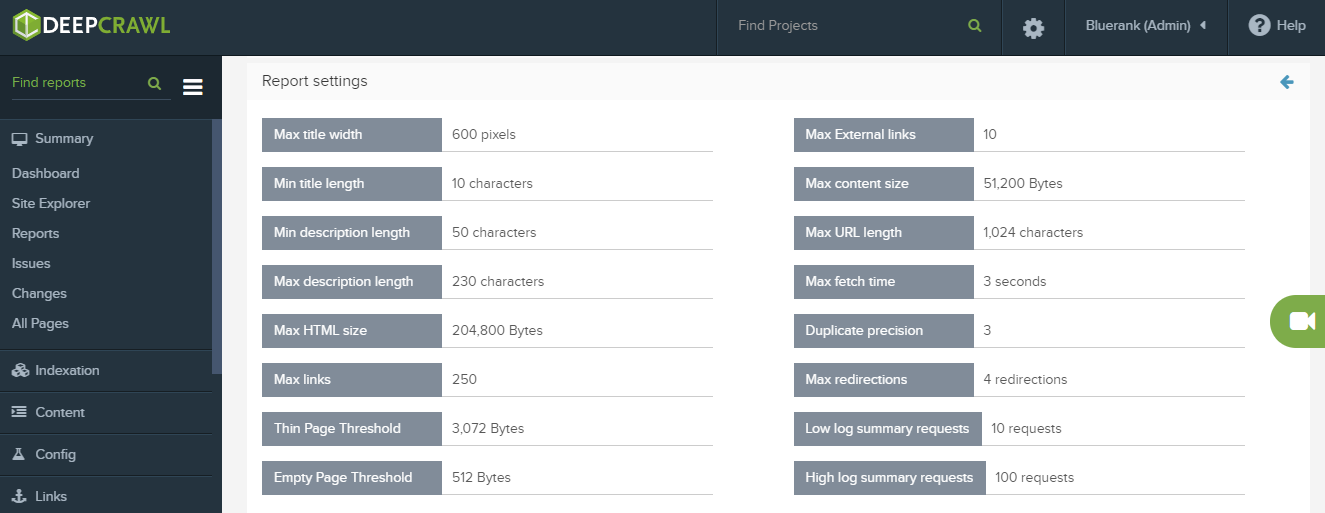
Deepcrawl pozwala na personalizacje ustawień dla każdego crawla (np. poprzez zwiększenie minimalnej wartości do wskazywania stron Thin Pages)
Pozwala to na znalezienie URLi o małej ilości lub braku treści w sekcji body. Przyglądając się efektom i skuteczności narzędzia muszę podkreślić jego przydatność. Praca nad stronami z małą ilością treści może przynieść duże i szybkie efekty z uwagi na fakt, że takie strony nie wykorzystują swojego potencjału SEO, a w przypadku ich dużego udziału w ogólnej liczbie stron serwisu mogą również obniżać jego ocenę algorytmiczną według Google. Crawl wielokrotnie wskazywał mi strony, o których nie miałem pojęcia na podstawie codziennej pracy nad serwisem, więc użycie go jest jak najbardziej wskazane.
4. Strony błędów 404
Funkcjonalność pozwalająca odnaleźć strony błędów 404 sama w sobie nie jest czymś, co wyróżnia Deepcrawl na tle innych narzędzi używanych przez specjalistów SEO czy Developerów. Błędy 404 zgłaszają nam m.in.: Screaming Frog, Ahrefs, Majestic czy Google Search Console.
Dlaczego więc o tym piszę? Po pierwsze praca nad błędami 404 w serwisie jest istotna w codziennej pracy każdego specjalisty SEO. Natomiast po drugie Deepcrawl daje swoim użytkownikom możliwość podpięcia innych narzędzi, które pozwalają zwiększyć ilość danych, które przeanalizuje. Wykorzystanie Google Analytics, Google Search Console, backlinków z Majestic lub Ahrefs czy pliku z logami pozwalają wyciągnąć kompleksowe dane, zdecydowanie przewyższające możliwości, jakie daje sam „czysty” crawl serwisu. Ciekawą metryką jest również graficzne przedstawienie stron niezgłaszających kodu 200, dzięki czemu możemy szybko zaobserwować, czy największym problemem naszego serwisu jest duża ilość 400-tek, 500-tek czy może zbyt duża liczba przekierowań.
5. Kompleksowa analiza przekierowań
A propos przekierowań – w tym przypadku również otrzymujemy olbrzymie wsparcie, gdyż Deepcrawl prezentuje dużą ilość metryk dotyczącą redirectów i prowadzi użytkownika za rękę wskazując najistotniejsze możliwości optymalizacyjne.
Narzędzie wskazuje:
- Ilość przekierowań – możemy więc skontrolować, czy przekierowania w naszym serwisie nie stanowią zbyt dużego udziału wszystkich stron,
- Przekierowania posiadające kod inny niż 301 (np. 302 lub 307, czyli przekierowania tymczasowe),
- Przekierowania łańcuszkowe,
- Pętle przekierowań,
- Przekierowania na niedostępne strony (np. 404-ki),
- Przekierowania wykonane za pomocą JavaScript lub Meta refresh.
Oczywiście każda z tych metryk i zgłaszanych przez Deepcrawl problemów (Issues) powinna zostać poddana analizie i ocenie specjalisty, ale zbiór oferowanych przez narzędzie klasyfikacji zbieranych danych jest imponujący.
6. Poprawność wdrożenia linków kanonicznych
Linki kanoniczne oraz ich potencjał w SEO często są ignorowane przez mniej doświadczonych specjalistów. Crawlując serwis za pomocą DeepCrawl praktycznie nie mamy możliwości, żeby zapomnieć o, lub zignorować kwestię canonicali, gdyż zostały opatrzone kompleksowymi metrykami, które bardzo szczegółowo wgryzają się w ten aspekt działania serwisu. Za pomocą DC sprawdzisz:
- Czy strona posiada link kanoniczny i czy jest on poprawny (czy nie występują podwójne canonicale lub idąc dalej – czy nie ma konfliktu między nimi),
- Czy link kanoniczny odsyła do poprawnych zasobów (czy kod odpowiedzi serwera to 200, czy strona, do której odsyła link jest indeksowana),
- Czy strona, do której odsyła link kanoniczny nie jest „sierotą”, czyli czy posiada odnośniki w strukturze serwisu.
Jedyne czego może brakować w metrykach prezentowanych przez narzędzie to podział na linki self-canonical oraz odsyłające do innych stron w serwisie.
7. Poprawność wdrożenia protokołu HTTPS
Wdrożyłeś protokół HTTPS i nie jesteś pewien czy na pewno wszystkie zasoby zostały przekierowane na adresy z szyfrowanym połączeniem? Zastanawiasz się czy wszystkie linki wewnętrzne (a masz ich całe mnóstwo), nie mówiąc już o canonicalach czy hreflangach, zostały zmienione na te z odpowiednim protokołem?
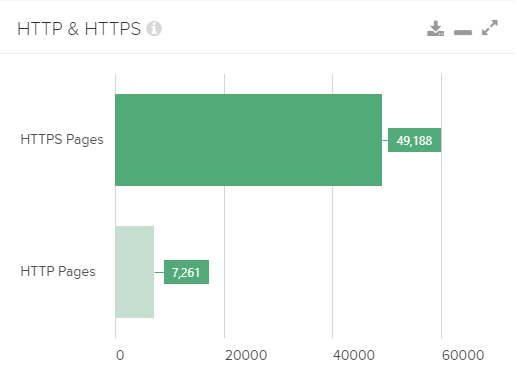
Dashboard prezentuje wiele metryk, w tym jedna prezentująca przekrój ilości adresów z protokołem HTTPS w porównaniu z HTTP
DeepCrawl bardzo prosto i przystępnie prezentuje zestawienie przeskanowanych adresów URL z podziałem na te z protokołem http i https, w związku z czym masz pewność, że znajdziesz wszystkie, nawet te najbardziej ukryte, zasoby ze starym protokołem http. Funkcjonalność jest przydatna również w przypadku serwisów, które mają wdrożonego HTTPS-a od dłuższego czasu. Wielokrotnie natrafiałem na przypadki linków wewnętrznych do wersji http serwisu, w przypadkach, gdy wydawałoby się, że developerzy dopilnowali wszystkiego w czasie dawnej migracji.
8. Obecność i poprawność hreflangów
SEO w serwisach międzynarodowych niesie ze sobą dodatkowe wyzwania w pracy nad optymalizacją serwisów. Jednym z nich są m.in. atrybuty hreflang, które powinny wskazywać zależność między różnymi wersjami językowymi danej strony. Oczywiście również w tym przypadku możemy liczyć na wsparcie DeepCrawla. W czym pomoże nam narzędzie?
- Wskaże nam strony z/bez hreflangów w kodzie strony
- Pokaże nam przypadki niepoprawnej implementacji hreflangów (np. linki z atrybutem hreflang w sekcji body strony)
- Przedstawi hreflangi odsyłające do nieistniejących zasobów (np. stron błędu 404)
- Przedstawi nieindeksowane strony posiadające hreflangi
W przypadku analiz hreflangów mam tylko jedną uwagę, a mianowicie – nie powinniśmy traktować DeepCrawla jako wyroczni w tej kwestii. Narzędzie nie analizuje hreflangów kompleksowo i nie uwzględnia, czy np. dana strona posiada hreflang zwrotny, co jest nieodzowne, żeby roboty Google odpowiednio zinterpretowały te instrukcje.
9. Głębokość struktury serwisu
Kolejna świetna funkcjonalność DeepCrawla, która w bardzo przystępny sposób pokazuje ogólną głębokość struktury serwisu (mierzoną za pomocą ilości kliknięć od strony startowej crawla, którą najczęściej jest strona główna, niezbędną do dostania się do danych stron), ale również wskazuje, na którym poziomie znajduje się dany adres URL.
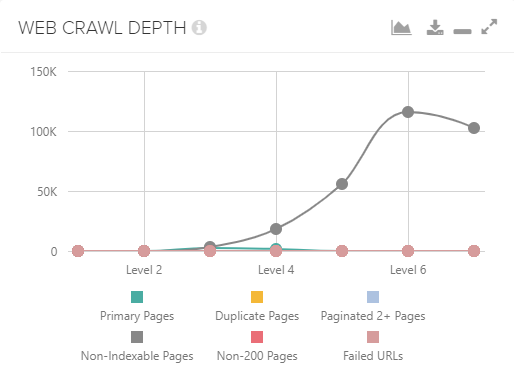
Przystępna forma prezentowania danych – w powyższym wypadku jest to struktura/głębokość serwisu
Użytkownik potrzebuje sześciu kliknięć, żeby dostać się do ważnej kategorii produktów? Artykuł, na którego popularności Ci zależy jest zakopany w podkategorii, do której dostaniesz się dopiero po czterech kliknięciach? To mogą być powody, dla której kluczowe dla Twojego biznesu strony osiągają słabsze niż zakładane wyniki, a Deepcrawl Ci to powie. Sprytne!
10. Monitoring linków – przychodzących i wychodzących
Linkowanie… w ostatnich latach, wraz z ewolucją SEO, nie jest już tak gorącym hasłem jak kilka lat temu, ale cały czas odgrywa duże znaczenie. Kontrola nad linkami przychodzącymi do serwisu jest bardzo istotna, a w ramach abonamentu DeepCrawl udostępnia swoim użytkownikom darmową funkcjonalność, która pozwala na przeanalizowanie do 30 tysięcy linków przychodzących znajdujących się w bazie danych Majestic lub analizę pliku z linkami przygotowanymi przez specjalistę.
W kwestii linkowania wewnętrznego narzędzie jest jeszcze bardziej rozwinięte: pokaże wszystkie linki do stron z błędami czy przekierowaniami, pozwoli zmonitorować linki nofollow w witrynie, wskaże strony, które posiadają zbyt dużą liczbę linków w kodzie (zarówno tych zewnętrznych, jak i wewnętrznych), pokaże linki wychodzące, które kierują do nieistniejących zasobów czy pokaże omawiane już wcześniej błędne linki znajdujące się w sitemapie serwisu.
11. Rozmiar stron w serwisie
W kwestii bardzo popularnego performance’u, czyli szybkości i wydajności serwisu, Deepcrawl nie jest narzędziem, dającym funkcjonalności porównywalne do oferowanych przez Google Lighthouse czy WebPageTest.org. W porównaniu do powyższych narzędzi prezentuje stosunkowo mało danych, ale jest w stanie np. wskazać strony, które potrzebują zbyt dużo czasu do załadowania.
Istotną funkcjonalnością jest natomiast prezentowanie danych dot. wielkości pliku HTML danych stron. W przypadku serwisów ecommerce częstym problemem są duże pliki HTML np. na stronach kategorii. Deepcrawl jest w stanie wskazać takie strony, wobec których przydałoby się „odchudzenie” HTML-a, chociażby przez przeniesienie inline’owych skryptów do zewnętrznych plików lub bardziej optymalne przepisanie kodu.
12. Synchronizacja danych z innymi narzędziami
Last but not least, czyli fakt, że funkcjonalność crawlera to jedynie część możliwości, jakie daje nam DeepCrawl. Wspominane powyżej wykorzystanie danych pobieranych za pomocą API Majestica to tylko część dodatkowych źródeł danych, które narzędzie może przeanalizować, a są to dane z:
- Google Search Console
- Google Analytics
- Sitemapa/y serwisu
- Linki pobrane z API Majestic lub wgrane ręcznie
- Logi serwerowe (również wgrane za pomocą API lub ręcznie)
- Wgrana ręcznie lista URL-i
Sam crawl serwisu jest świetnym źródłem informacji dot. jego kondycji, ale możliwości, jakie daje podpięcie dodatkowych źródeł danych daje prawie kompleksowy obraz, który może posłużyć do przeprowadzenia niesamowicie złożonego audytu.
Deepcrawl to prawdziwy kombajn, który niezwykle ułatwia pracę przy analizie serwisu. Każdy specjalista powinien jednak pamiętać, że narzędzie nie podaje gotowych rozwiązań i rekomendacji, ale jedynie zgłasza najważniejsze problemy w serwisie, których rozwiązanie może być różne w zależności od analizowanego przypadku. Dopiero odpowiednia interpretacja wykonana przez specjalistę czyni narzędzie przydatnym. Po kilkunastu miesiącach pracy z Deepcrawlem ciężko jest mi wyobrazić sobie wykonywanie audytów czy analiz bez tego narzędzia, które ułatwia i niesamowicie optymalizuje czas pracy. A wady? Narzędzie nie należy do najtańszych, roczny abonament zdecydowanie przewyższa sumę, jaką musimy przeznaczyć chociażby na analogiczną licencję do Screaming Froga, co może być nie do przeskoczenia np. dla części freelancerów. Jeśli nie jest to przeszkodą nie do pokonania – zdecydowanie warto!

